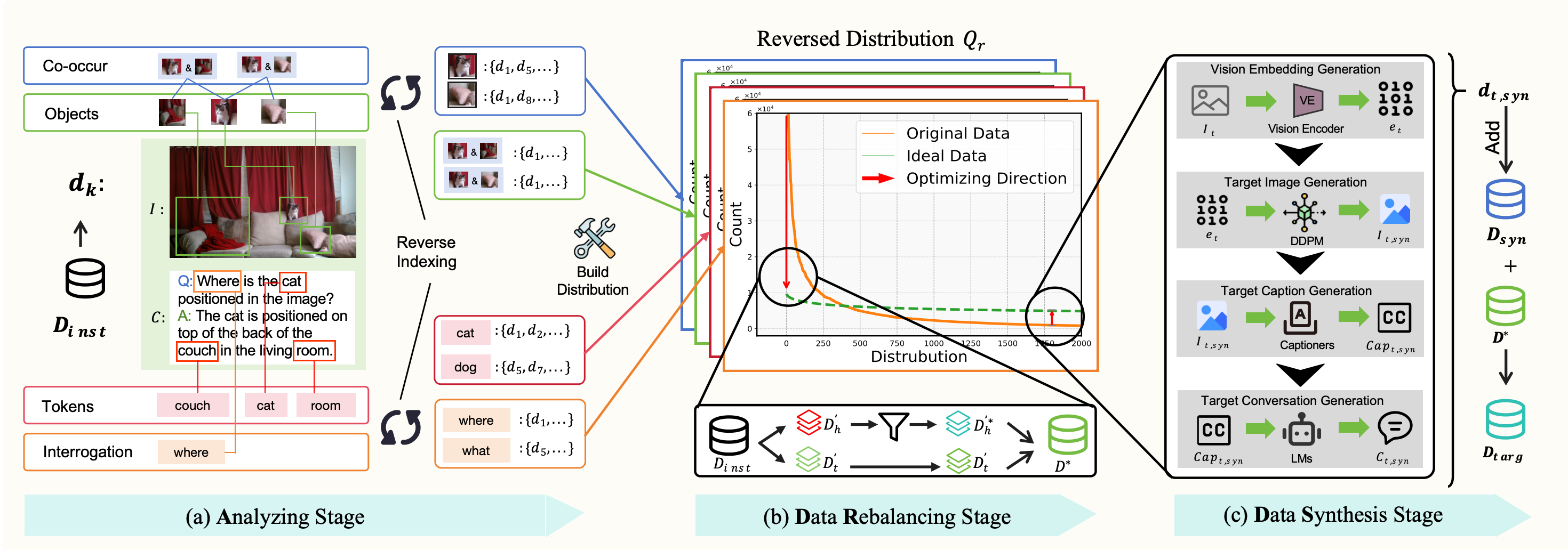
Large Vision-Language Models (LVLMs) have achieved significant progress in combining visual comprehension with language generation. Despite this success, the training data of LVLMs still suffers from Long-Tail (LT) problems, where the data distribution is highly imbalanced. Previous works have mainly focused on traditional VLM architectures, i.e., CLIP or ViT, and specific tasks such as recognition and classification. Nevertheless, the exploration of LVLMs (e.g., LLaVA) and more general tasks (e.g., Visual Question Answering and Visual Reasoning) remains under-explored. In this paper, we first conduct an in-depth analysis of the LT issues in LVLMs and identify two core causes: the overrepresentation of head concepts and the underrepresentation of tail concepts. Based on the above observation, we propose an Adaptive Data Refinement Framework (ADR), which consists of two stages: Data Rebalancing (DR) and Data Synthesis (DS). In the DR stage, we adaptively rebalance the redundant data based on entity distributions, while in the DS stage, we leverage Denoising Diffusion Probabilistic Models (DDPMs) and scarce images to supplement underrepresented portions. Through comprehensive evaluations across eleven benchmarks, our proposed ADR effectively mitigates the long-tail problem in the training data, improving the average performance of LLaVA 1.5 relatively by 4.36%, without increasing the training data volume.
@article{song2025head,
title={From head to tail: Towards balanced representation in large vision-language models through adaptive data calibration},
author={Song, Mingyang and Qu, Xiaoye and Zhou, Jiawei and Cheng, Yu},
journal={arXiv preprint arXiv:2503.12821},
year={2025}
}


